
The following post is intended for users that are new to Databricks and wish to get a crash course:
Sales
- Databricks is positioned as a Data Science and Machine Learning Platform by Gartner, other players in the same space include SAS, Alteryx. They describe their product as a Unified Data Analytics Platform.
- They have received significant venture capital investment since 2014 with the most recent Series F funding being received in late 2019.
- Microsoft are an investor in Databricks and offers it in the Azure Platform to compliment Azure Synapse
- Databrick’s pitch is that it is complete solution that includes:
- Data ingestion and preparation
- Feature engineering
- Model creation, training and testing
- Monitoring
- Collaboration
- Workflows
Platform
- Apache Spark is the underlying platform. This is going to polarise potential users based on their background. It is more suited to technical users and definitely not as friendly as say Alteryx.
- One-click setup is currently available in Azure or AWS.
- Languages supported include Python, R, SCALA and SQL
- Databricks cluster and the Azure Synapse access a common Blob storage container to exchange data between these two systems
Features and Concepts
- Delta Lake is a layer that provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Architecturally is sits on top of the data lake.
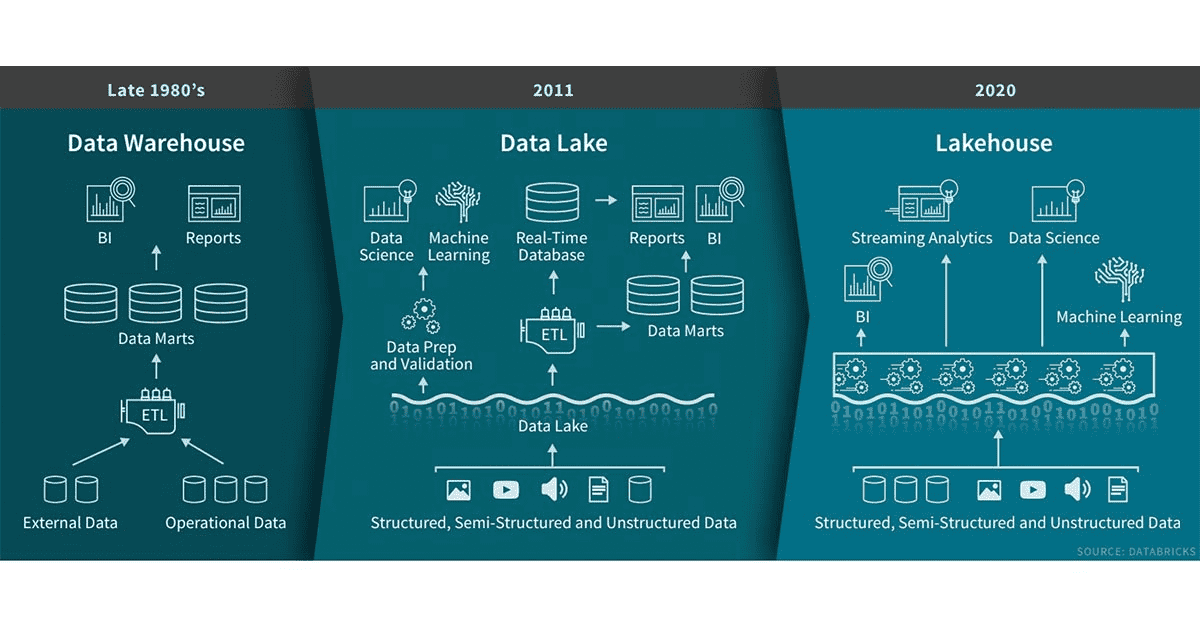
- Databricks has the feature of a Lakehouse pattern as does Azure Snapse service. A Lakehouse can be described as a Data Lake enabled with features to support analytics. It is intended to avoid the cost and overhead of a Data Warehouse:
- A key feature is the concept of a Notebook. A notebook is a browser-based interface to a document (i.e. notebook) that contains runnable code, visualizations, etc. This is the primary location where a user would work.
- Clusters come in two flavours:
- All-purpose – Use when analyzing data in notebooks.
- Job – Running automated jobs.
- A Pool is a set of idle, ready-to-use instances that a Cluster is attached to. It reduce start and auto-scaling times.
- A Job is a way of running a notebook or JAR. This can be done immediately, or on a scheduled basis.
- Databricks Scheduler creates and terminates Job Clusters when a scheduled job runs.
- Libraries are objects that can be accessed from notebooks or jobs. Libraries can be written in Python, Java, Scala, and R and installed by users to extend their notebook/job.
- Conventional BI tools such as Tableau, Power BI, Alteryx, etc. can connect via JDBC/ODBC.
- A Dataset is a distributed collection of data. It is provides the benefits of Resilient Distributed Datase (RDDs) with the benefits of Spark SQL’s optimized execution engine.
- A DataFrame is a Dataset organized into named columns. It can be thought of being a table in a database.
- Data is Loaded into Databricks via a number of approaches, including
- Browser-based file uploads.
- Pulling data from a source like Azure Blob Storage or AWS S3. Examples can be found here.
- Structured Streaming is available so that computation on streaming data in the same way as is done in batch mode.
- Machine Learning (ML) is facilitated by multiple popular libraries, like TensorFlow, PyTorch, Keras, and XGBoost
Users
Intended users include:
- Data scientists
- Data engineers
- Business analysts that have strong technical skills
Security
- Data is persisted within Databricks using the users own datastore and credentials.
- In the FAQs, the majority of points relate to security, for example persistence of data, cloud provider’s data rights, etc. Clearly it is a prominent concern when users review Databricks as a solution.
Code
Useful snippets
| Current Date | spark.range(1).select(current_date) |
| Configure Databricks Connect | databricks-connect configure |
For other FAQs check out DataBricks
